意思決定の仕方を機械は学べるか ~ 長期的な便益を最大化する強化学習の手法~
本稿では、まずビジネスにおいて従来型の机械学习モデルを活用する际に陥りがちな课题について説明します。また、その课题を解决する手法としての强化学习の要諦と、人间の意思决定の学习プロセスを模した特徴的な学习の仕方を概説します。
本稿では、まずビジネスにおいて従来型の机械学习モデルを活用する际に陥りがちな课题について説明します。また、その课题を解决する手法としての强化学习の要諦と、人间の意思决定の学习プロセ
「強化学習」は、囲碁で世界一のプレイヤーに勝利を収めたAlphaGoや、大規模言語モデルであるChat GPTの開発にも使われている機械学習の手法の1つです。強化学習は、これまでは主に限定的な領域に適用されていましたが、今後は多方面のビジネス領域に広がっていくと考えられます。特に、データドリブンでビジネス改善を推進する際、この手法の重要性はより増していくと思われます
本稿では、まずビジネスにおいて従来型の机械学习モデルを活用する际に陥りがちな课题について説明します。続いて、その课题を解决する手法としての强化学习の要諦と、人间の意思决定の学习プロセスを模した特徴的な学习の仕方を概説します。そのうえで、実际にホテルの客室の価格设定に强化学习を适用した実証例とその検証结果を绍介し、最后に强化学习のビジネスへの活用を今后加速させると考えられるシミュレータの必要性とその効果を解説します。
なお、本文中の意见に関する部分については、笔者の私见であることをあらかじめお断りいたします。
Point
1.従来的な机械学习モデルの落とし穴
ビジネスの意思决定は、多岐にわたる膨大な情报に基づいた判断が求められる。回帰分析などの従来的な机械学习モデルは、限定的な状况を基にした単発的な打ち手に留まり、长期的には必ずしも最善ではない可能性がある。したがって、より包括的に状况を加味したデータサイエンスの手法が求められる。
2.强化学习を活用した课题解消への试み
强化学习は、一定の期间内におけるベネフィットが最大限に达成されるように意思决定の仕方を学ぶ手法であり、単発的な改善とは根本的に异なる。具体的には、特定の状况における意思决定とその意思决定に対するフィードバックを受け取ることを繰り返して、何が成功で何が失败かを学习する。
この手法を、ホテルの客室の価格设定に适用?検証した结果、売上を最善となる代替アプローチよりも最大5%増加させることができた。これにより、强化学习がビジネス领域においても効果があることが确认された。
3.学习に不可欠な环境を提供するシミュレータの必要性
现在、适切な学习环境を提供するシミュレータ构筑が技术的に进歩してきている。シミュレータが构筑できると、强化学习モデルを学习させる効果的な训练环境となるデータを提供できるようになる。これは、强化学习をビジネスに応用する际に直面していた学习データの準备の课题が克服できることを意味し、强化学习の活用を促进すると考えられる。


Ⅰ. 従来型データサイエンス手法のさらなる先へ
近年、ビジネスの特定机能の支援に特化したデータサイエンスの活用や意思决定の高度化の事例が数多く见られます。たとえば、贩促においては贰颁サイトにおける商品レコメンドのアルゴリズム、物流领域においては最适なルート探索や最适な运行スケジュールの作成などです。これらの领域では、データサイエンスの活用がいわば高度にビジネスの意思决定と络まっており、担当领域の责任者は适切にデータサイエンスを活用できれば大きな武器を手にすることができます。
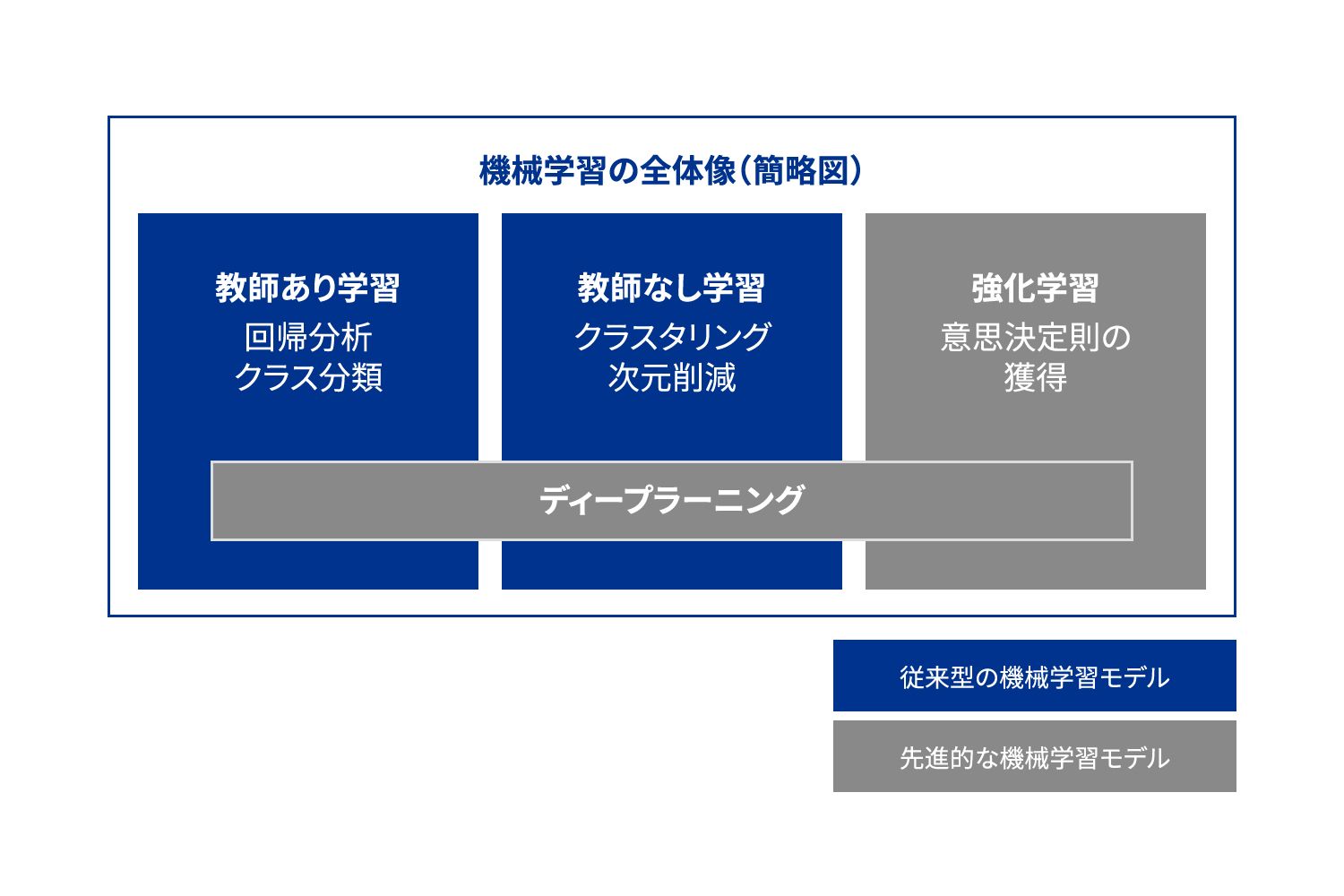
しかし、このようなデータサイエンスを使ったビジネス改善にはいくつかの落とし穴があり、それは理解されないまま利用されているか、见过ごされているようにも见受けられます。それゆえ、适用する手法の限界や课题を见极めることは非常に重要となります。ここでは简略的にいわゆる回帰分析などの「従来型の机械学习モデル」に焦点を当てて、その课题を见ていきます(図表1参照)。
まず1つ目の课题は、従来型の机械学习モデルが出す最适解は「近视眼的」になっている、あるいはその倾向が高くなっているということです(図表2参照)。
図表2 従来型の機械学習モデルの课题
| 课题 | 详细 |
|---|---|
| 近视眼的 | 直近の精度は高いものの、远い将来になるほど解の信頼性が下がりやすい |
| 単発的 | 継続的に连続した解ではなく、1つのタイミングにおける最适解になりがち |
| 局所的 | 个别最适な解となる倾向が强く、全体最适が损なわれやすい |
出所:碍笔惭骋作成
机械学习モデルは、基本的に过去データのパターンを学习することから、常に现时点にすぐ近い将来に対する予测や解が最も精度が高くなります。そのため少し先を见据えた判断というのは苦手な倾向にあります。
2つ目に、従来型の机械学习モデルは単発的で特定タイミングにおける最适解を导出しがちで、一定の期间における成果が最大となるような连続性を加味した判断というものも不得意としています。このような倾向性は、その场しのぎの判断となりやすいともいえます。
最後に3つ目の课题として、個別の領域でみると局所的なメリットはあっても、別の大きな問題を生んでしまうというケースも見受けられます。たとえば、利益を最大化するように広告や販促活動を最適化していたはずが、リピートする可能性の低いワンタイム顧客の利用を増やしてしまい、長期的に見れば利益が目減りしたなどです。
より長期的なビジネス改善を目指し、より複合的な意思決定をしていきたい担当責任者にとって、このような课题を残したままの利用は最善とはいえません。このような特定のタイミングにおけるスナップショットの解ではなく、できる限り包括的に状況を捉えた意思決定をデータサイエンスにより強化することは可能でしょうか。注目の「強化学習」という分析アプローチは、まさにこのような問題に1つの答えを提供するアプローチだといえます。
図表1 機械学習モデルの全体簡略図
出所:碍笔惭骋作成
Ⅱ.意思决定の仕方を学ばせる强化学习の要諦とその効果
强化学习をあえて一言で述べるならば、「ある问题に対して长期的な便益が最大化されるように最善の意思决定の仕方を学ぶ手法」です。この手法は日々异なるビジネスの状况を踏まえ、何が失败で、何が成功かを学习し、そのたびに何が最适かを考える人间の意思决定の学习プロセスを模しています。
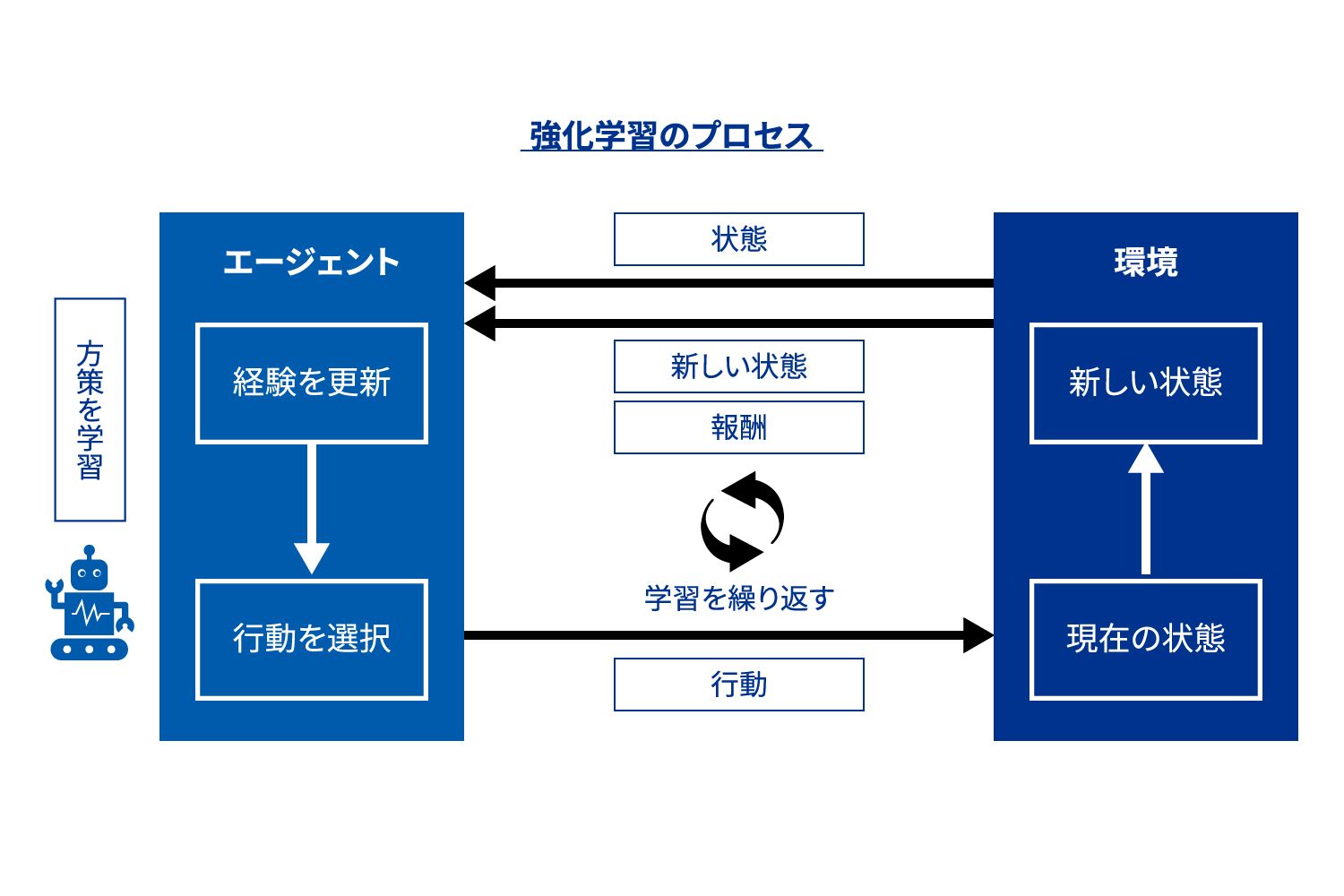
ここでは、重要となるキーワードの定義をしながら、強化学習の仕組みを説明します。まず強化学習では、行動や意思決定をする主体をエージェントと呼びます。このエージェントが、判断すべき内容であるタスク(環境)について意思決定を行い、それに対するフィードバックを報酬として受けることを繰り返して、意思決定のルールを学習します。より详细には、エージェントは状態と呼ばれる現在の状況を表す情報を把握したうえで意思決定を行い、その状態における行動の結果として報酬や新しい状態を引き出し、再度意思決定を行う、という過程を繰り返します(図表3参照)。こうしてエージェントが行動する環境を探索し、意思決定とその結果のデータを経験として学習することで、意思決定ルール(方策)を改善していくというわけです1。
図表3 強化学習において、エージェントが環境と相互作用して状態、行動、報酬をやり取りする様子
出所:碍笔惭骋作成
たとえば、ホテルにおける価格设定でいえば、ホテルにおける状态は现在の空室状况ならびにその时点での部屋価格、意思决定となる行动は部屋の価格设定、报酬はその価格で予约された部屋数に応じた収入となります。このプロセスにおいてエージェントは、报酬である収入が最大化されるような価格方针の学习を目指します。
ここで着目したいのは、強化学習の目的が、報酬の累積値を最大にする意思決定ルールを獲得することだという点です。つまり、短期的には報酬が低く損失になるとしても、長期的には報酬の累積が最大になることを目指すというわけです。具体的なビジネスの文脈で言えば、一度のアクションで得られる利益が低くとも、継続的にアクションを見直すことで利益の累積が最大になるような戦略を学習するということです。このように、累積の報酬を最大化するために意思決定ルールを学習するという仕組みは、従来型の機械学習モデルとは異なる強化学習の特徴です。そして、これが従来型の機械学習モデルを活用した際の课题への1つの改善の方向性を示すものと考えられます。
強化学習は、最近では大規模言語モデルであるChat GPTの開発にも使われている学習アルゴリズムとして注目を集めている手法です。適用には難しさがあるものの、今後はより広範な範囲で徐々に広がっていくと考えられています。これまでは、ビジネス領域外ではチェスや囲碁のような複雑なゲームで人間の能力を超える結果を出す事例、ビジネス領域では自動運転やロボット制御などにおける適用例がほとんどでしたが、最近ではeコマースにおける価格設定の事例など、ビジネスのオペレーショナルな問題にも適用されるケースが出てきました。このような状況を踏まえ、ビジネスのより複雑な意思決定が必要な領域においても、その効果を検証するような状況や機運が高まってきたと考えられます。
実際、強化学習を効果的な形でビジネスに適用することが可能なのかを確認するために、乐鱼(Leyu)体育官网ではホテルの客室の価格設定に強化学習を適用し、客室予約による売上の改善効果の検証を行いました。簡易化のため一定の仮定の下、客室の予約受付開始日から宿泊当日まで、空室状況ならびにその時点での客室価格に応じて、一定の頻度で客室価格を強化学習モデルが設定するような設定です。ゴールは、対象の宿泊日の予約がもたらす累積売上を最大にする価格設定戦略の学習です。学習には、DQN(Deep Q-Network)という強化学習にディープラーニングを適用した手法の祖ともいえるアルゴリズムを用いました。結果は、DQNを適用して訓練したエージェントのほうが、顧客予算を反映している固定価格よりも最大5%の売上増加を見込めることが実証できました。これは、強化学習モデルが、さまざまな価格帯とその際の客室売上を効率的に学習し、最終的に上記の固定価格よりも売上を増加させる価格とその提示タイミングを特定できるようになったことを意味します。この実証結果から、ビジネス領域における強化学習の適用は現実的になったと言えそうです。
Ⅲ.学习に不可欠な环境を提供するシミュレータの必要性
ここまで、多くの强化学习のメリットとその効果を述べてきましたが、现在はまだ主要なアプローチとは言えません。その理由は、ディープラーニングなどと同様、学习の仕组みや背景がブラックボックス化されてしまうこと、技术面で强化学习の报酬の设定の仕方やタスクの定义方法などの难しさが挙げられます。これらに加え、ビジネスへの活用という観点で强化学习を妨げてきた最も大きな理由は、学习データの準备の难しさにあります。
機械学習モデルを訓練するには、一般に相当量のデータを要します。なかでも強化学習の枠組みでは、エージェントが環境のなかで意思決定をし、報酬または罰則の形でフィードバックを受けることによって意思決定の仕方を学習することから、膨大なデータサンプルを必要とし、最適な性能を達成するためには数十万回規模の学習が欠かせません。そのためには適切な訓練環境が必要になりますが、そこにも课题があります。理想的な訓練環境は、実際のビジネスに影響を与えることなしに、エージェントが自由に試行錯誤をして学習できることですが、現実世界でそのような環境を用意することは不可能に近いでしょう。
この课题を克服するためには、強化学習エージェント用の安全で効果的な訓練環境を提供するシミュレータを開発することが有用です。近年、この技術の発展から強化学習モデルを学習させやすくなることが見込まれており、実際に上述したホテルの価格設定の検証にも、この手法を適用しました。
シミュレータは、現実に即した形である程度详细を簡略化しながら、eコマース、接客業、食料品販売業などのさまざまな業界の状況を仮想的に作り上げ、強化学習でエージェントを訓練するための自由度の高い環境を提供します。作り方としては、ベースとなるシミュレータに対して、領域における専門知識と利用可能な情報(商品ラインナップ、マーケティング施策、顧客行動特性など)など購買特性を反映するよう調整し、業界の販売環境を正確に再現するようなシミュレータに仕立て上げます。また、各商材の性質によって異なるシナリオを想定することも可能です。たとえば、賞味期限のある食品には期限間際に頻繁に割引が行われるという傾向を、電化製品などには新しいモデルが導入されれば流行遅れになるという傾向を、比較的自由に反映することができます。
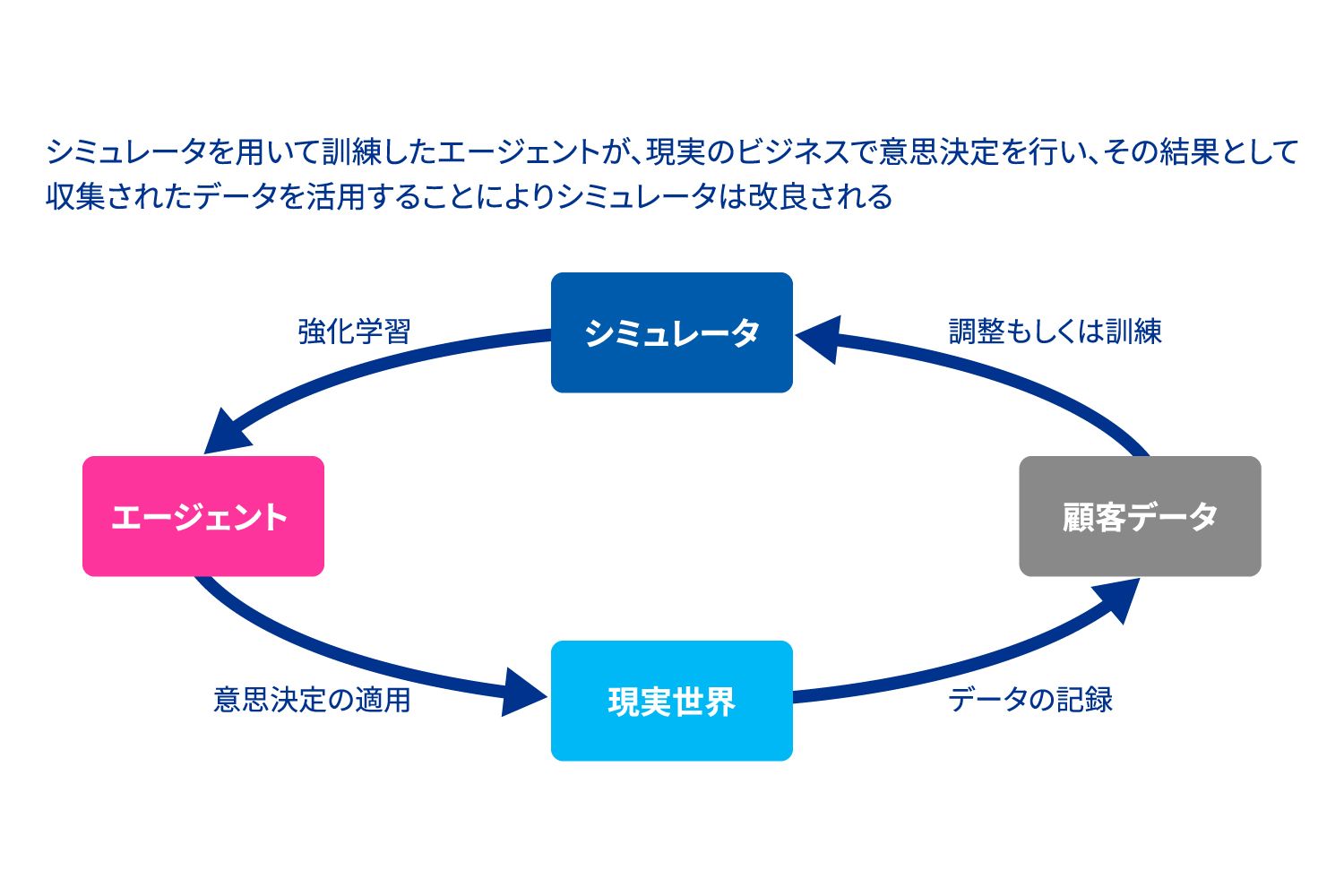
このように作り上げたシミュレーション环境で强化学习エージェントが学习し、その结果得られた行动の结果は、シミュレータをさらに改善するために使用され、结果としてエージェントの学习の改善をもたらします。现実世界とシミュレータからのフィードバックの下で、エージェントの意思决定は絶えず改良されます。エージェントとシミュレータが运用している间、常にシミュレータ自体も改良されていくのです(図表4参照)。
このシミュレータの作り込みが容易になればなるほど、强化学习という手法も活用が进み、回帰分析のような机械学习モデルや数理最适化など比较的トラディショナルな手法の一歩先に进めることが期待できます。
図表4 ダイナミックプライシングシミュレータ
出所:碍笔惭骋作成
Ⅳ.さいごに
本稿では、机械学习モデルのなかでも先进的な强化学习を取り上げました。比较的トラディショナルなアプローチは长期目线に立って意思决定をするのが难しいですが、强化学习には実际の人间のような意思决定を学ぶという仕组みがあります。强化学习は、现在もさまざまな领域で発展し続けており、新しいアルゴリズムやアプローチの开発も进んでいます。これからのビジネスにおける意思决定におけるデータサイエンス活用の1つの有効なアプローチとして、强化学习は今后、积极的に検讨されていくことでしょう。
1 ここで説明する設定は、厳密には「オンライン強化学習」と呼ばれています。
执笔者
乐鱼(Leyu)体育官网 FAS
田中 勇輝/マネージャー
碍笔惭骋アドバイザリーライトハウス
小澤 友美/シニアデータサイエンティスト

